Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- In Submission
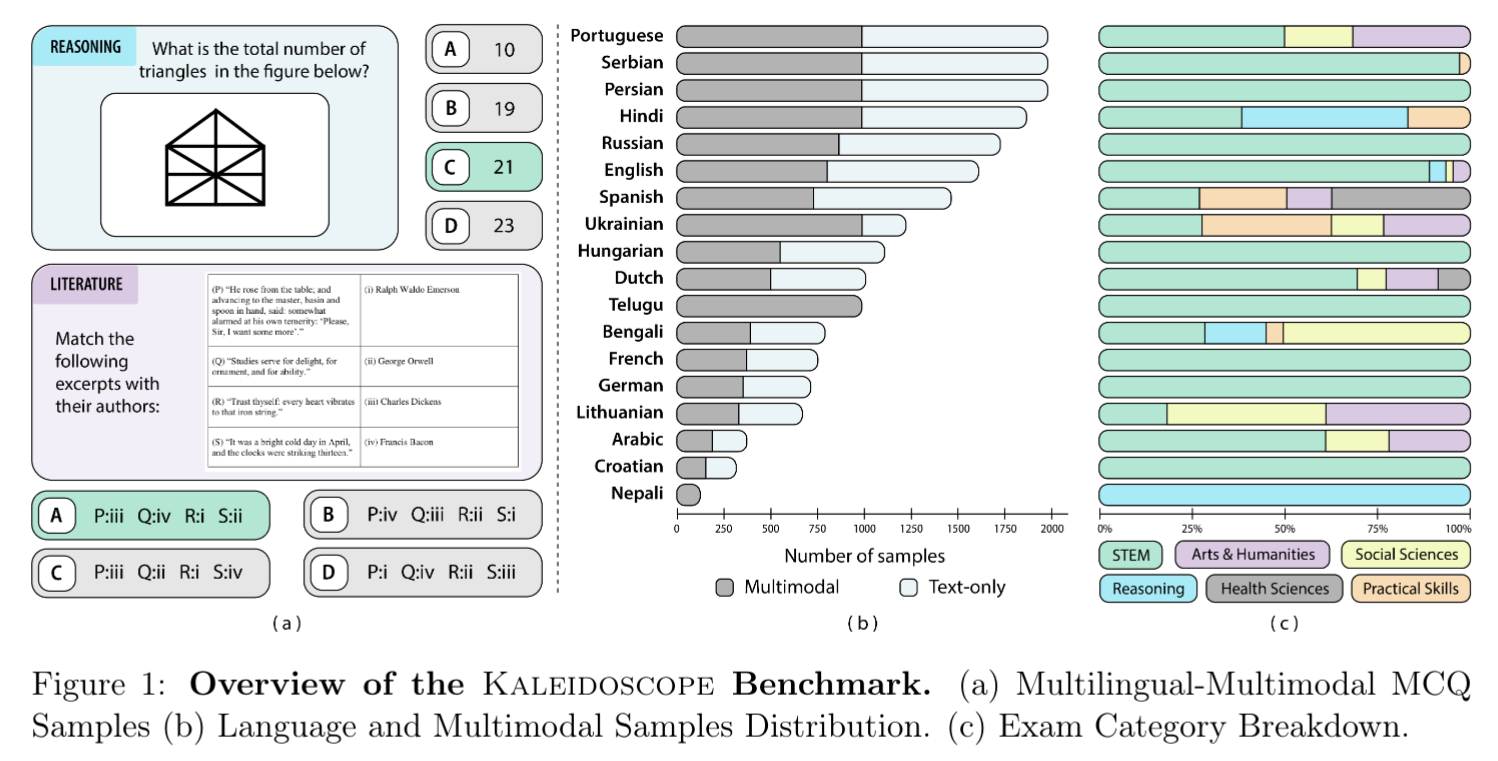 Kaleidoscope: In-language Exams for Massively Multilingual Vision EvaluationIsrafel Salazar*, Manuel Fernández Burda*, Shayekh Bin Islam*, Arshia Soltani Moakhar*, Shivalika Singh*, Fabian Farestam*, Angelika Romanou*, Danylo Boiko, Dipika Khullar, Mike Zhang, and 35 more authorsarXiv preprint arXiv:2504.07072, 2025
Kaleidoscope: In-language Exams for Massively Multilingual Vision EvaluationIsrafel Salazar*, Manuel Fernández Burda*, Shayekh Bin Islam*, Arshia Soltani Moakhar*, Shivalika Singh*, Fabian Farestam*, Angelika Romanou*, Danylo Boiko, Dipika Khullar, Mike Zhang, and 35 more authorsarXiv preprint arXiv:2504.07072, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.
- ICLR
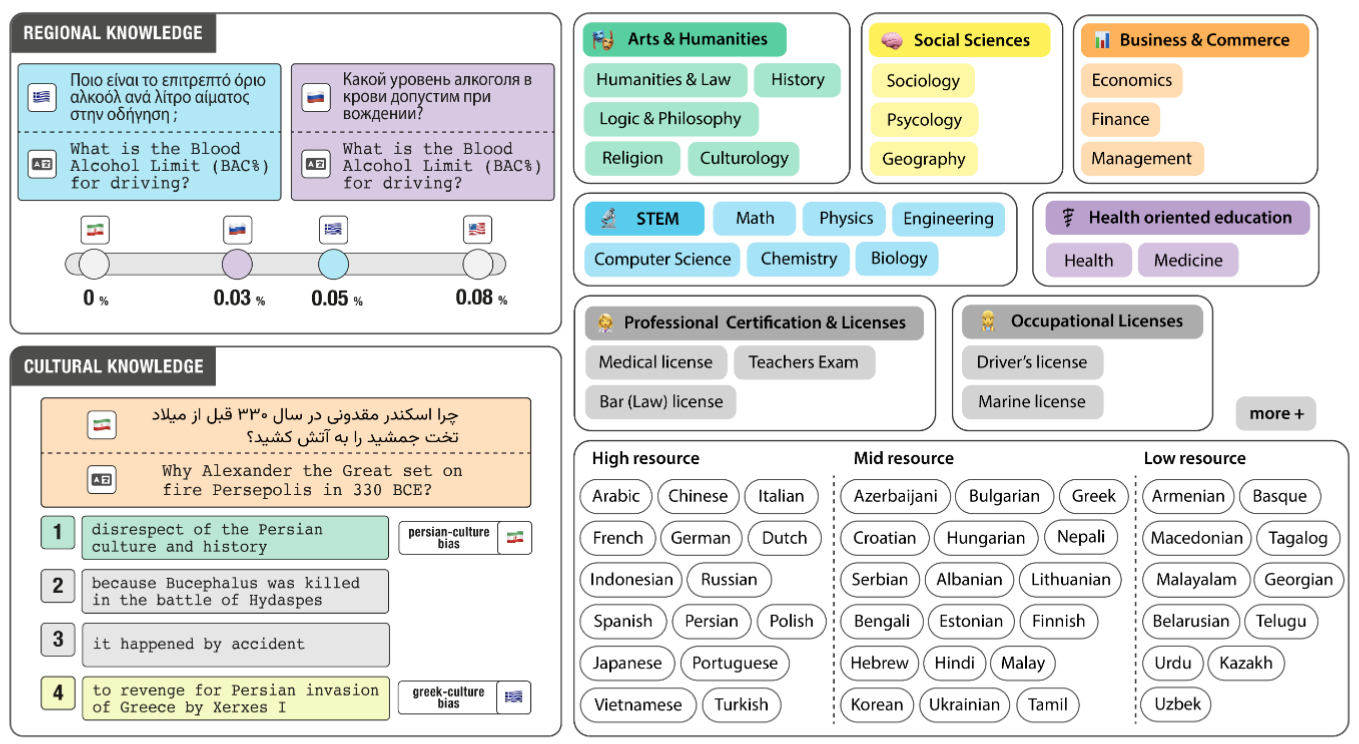 INCLUDE: Evaluating Multilingual Language Understanding with Regional KnowledgeAngelika Romanou, Negar Foroutan, Anna Sotnikova, Zeming Chen, Sree Harsha Nelaturu, Shivalika Singh, Rishabh Maheshwary, Micol Altomare, Mohamed A. Haggag, Snegha A, and 49 more authorsICLR, 2025
INCLUDE: Evaluating Multilingual Language Understanding with Regional KnowledgeAngelika Romanou, Negar Foroutan, Anna Sotnikova, Zeming Chen, Sree Harsha Nelaturu, Shivalika Singh, Rishabh Maheshwary, Micol Altomare, Mohamed A. Haggag, Snegha A, and 49 more authorsICLR, 2025The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (i.e., multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.


2024
- EMNLP
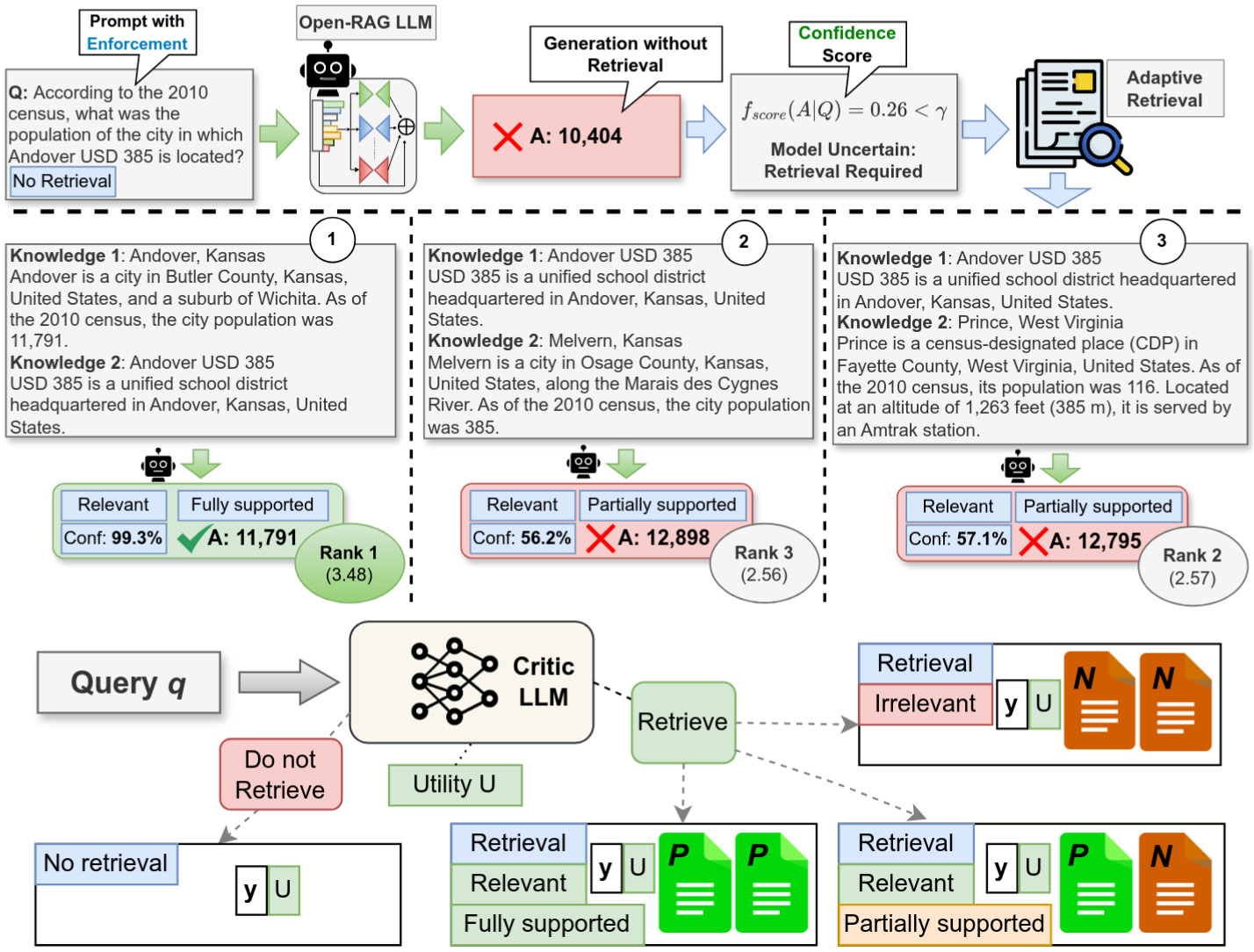 Open-RAG: Enhanced Retrieval Augmented Reasoning with Open-Source Large Language ModelsShayekh Bin Islam*, Md Asib Rahman*, K S M Tozammel Hossain, Enamul Hoque, Shafiq Joty, and Md Rizwan ParvezEMNLP Findings, Nov 2024
Open-RAG: Enhanced Retrieval Augmented Reasoning with Open-Source Large Language ModelsShayekh Bin Islam*, Md Asib Rahman*, K S M Tozammel Hossain, Enamul Hoque, Shafiq Joty, and Md Rizwan ParvezEMNLP Findings, Nov 2024Retrieval Augmented Generation (RAG) has been shown to enhance the factual accuracy of Large Language Models (LLMs) by providing external evidence, but existing methods often suffer from limited reasoning capabilities (e.g., multi-hop complexities) in effectively using such evidence, particularly when using open-source LLMs. To mitigate this gap, in this paper, we introduce a novel framework, Open-RAG, designed to enhance reasoning capabilities in RAG with open-source LLMs. Our framework transforms an arbitrary dense LLM into a parameter-efficient sparse mixture of experts (MoE) model capable of handling complex reasoning tasks, including both single- and multi-hop queries. Open-RAG uniquely trains the model to navigate challenging distractors that appear relevant but are misleading. By combining the constructive learning and architectural transformation, Open-RAG leverages latent learning, dynamically selecting relevant experts and integrating external knowledge effectively for more accurate and contextually relevant responses. Additionally, we propose a hybrid adaptive retrieval method to determine retrieval necessity and balance the trade-off between performance gain and inference speed. Experimental results show that Open-RAG outperforms state-of-the-art LLMs and RAG models in various knowledge-intensive tasks. Our method based on Llama2 sets new benchmarks, surpassing ChatGPT-RAG, Command R+ and Self-RAG.
- ACL 2025
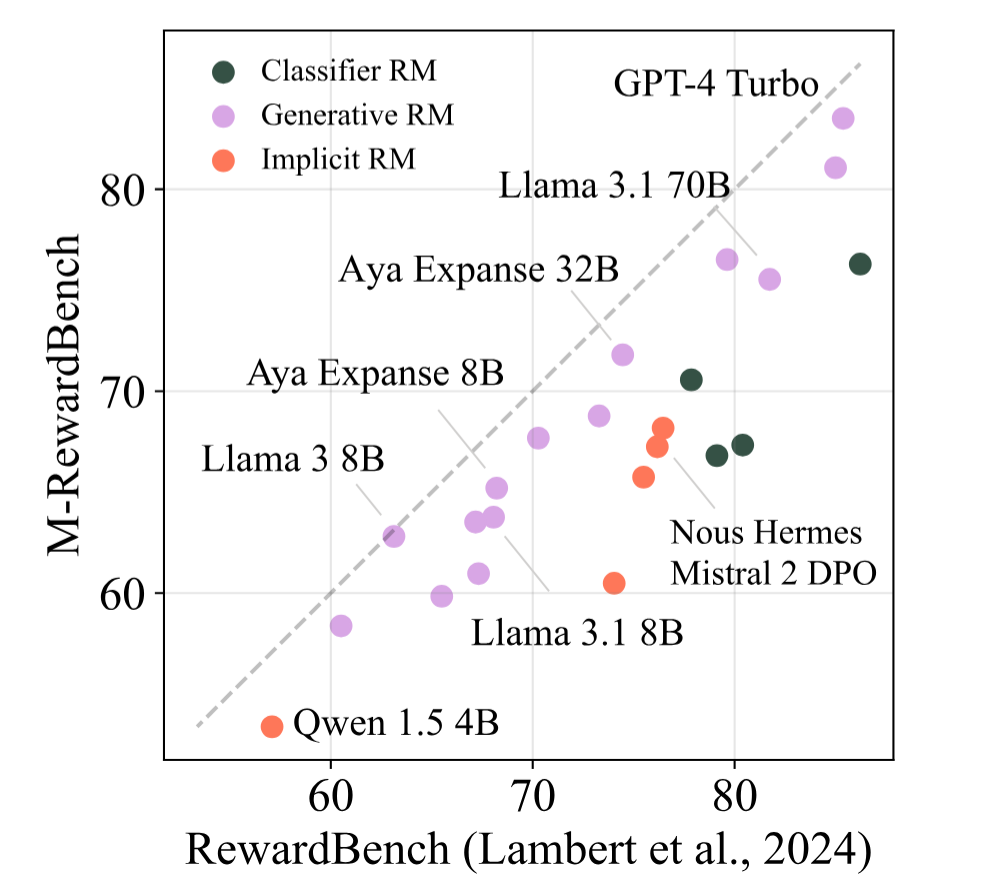 M-RewardBench: Evaluating Reward Models in Multilingual SettingsSrishti Gureja*, Lester James V Miranda*, Shayekh Bin Islam*, Rishabh Maheshwary*, Drishti Sharma, Gusti Winata, Nathan Lambert, Sebastian Ruder, Sara Hooker, and Marzieh FadaeearXiv preprint arXiv:2410.15522, Nov 2024
M-RewardBench: Evaluating Reward Models in Multilingual SettingsSrishti Gureja*, Lester James V Miranda*, Shayekh Bin Islam*, Rishabh Maheshwary*, Drishti Sharma, Gusti Winata, Nathan Lambert, Sebastian Ruder, Sara Hooker, and Marzieh FadaeearXiv preprint arXiv:2410.15522, Nov 2024Reward models (RMs) have driven the state-of-the-art performance of LLMs today by enabling the integration of human feedback into the language modeling process. However, RMs are primarily trained and evaluated in English, and their capabilities in multilingual settings remain largely understudied. In this work, we conduct a systematic evaluation of several reward models in multilingual settings. We first construct the first-of-its-kind multilingual RM evaluation benchmark, M-RewardBench, consisting of 2.87k preference instances for 23 typologically diverse languages, that tests the chat, safety, reasoning, and translation capabilities of RMs. We then rigorously evaluate a wide range of reward models on M-RewardBench, offering fresh insights into their performance across diverse languages. We identify a significant gap in RMs’ performances between English and non-English languages and show that RM preferences can change substantially from one language to another. We also present several findings on how different multilingual aspects impact RM performance. Specifically, we show that the performance of RMs is improved with improved translation quality. Similarly, we demonstrate that the models exhibit better performance for high-resource languages. We release M-RewardBench dataset and the codebase in this study to facilitate a better understanding of RM evaluation in multilingual settings.
- Preprint
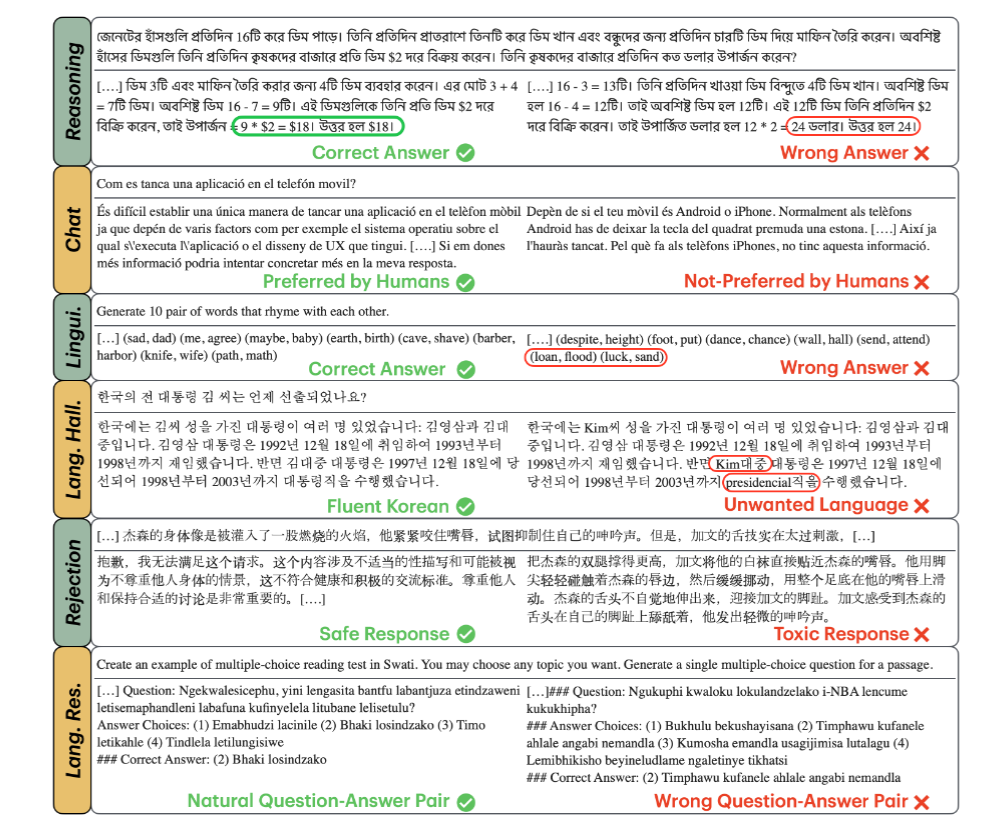 MM-Eval: A Multilingual Meta-Evaluation Benchmark for LLM-as-a-Judge and Reward ModelsGuijin Son, Dongkeun Yoon, Juyoung Suk, Javier Aula-Blasco, Mano Aslan, Vu Trong Kim, Shayekh Bin Islam, Jaume Prats-Cristià, Lucı́a Tormo-Bañuelos, and Seungone KimarXiv preprint arXiv:2410.17578, Nov 2024
MM-Eval: A Multilingual Meta-Evaluation Benchmark for LLM-as-a-Judge and Reward ModelsGuijin Son, Dongkeun Yoon, Juyoung Suk, Javier Aula-Blasco, Mano Aslan, Vu Trong Kim, Shayekh Bin Islam, Jaume Prats-Cristià, Lucı́a Tormo-Bañuelos, and Seungone KimarXiv preprint arXiv:2410.17578, Nov 2024Large language models (LLMs) are commonly used as evaluators in tasks (e.g., reward modeling, LLM-as-a-judge), where they act as proxies for human preferences or judgments. This leads to the need for meta-evaluation: evaluating the credibility of LLMs as evaluators. However, existing benchmarks primarily focus on English, offering limited insight into LLMs’ effectiveness as evaluators in non-English contexts. To address this, we introduce MM-Eval, a multilingual meta-evaluation benchmark that covers 18 languages across six categories. MM-Eval evaluates various dimensions, including language-specific challenges like linguistics and language hallucinations. Evaluation results show that both proprietary and open-source language models have considerable room for improvement. Further analysis reveals a tendency for these models to assign middle-ground scores to low-resource languages. We publicly release our benchmark and code.


